
I have watched the same cycle run for twenty-five years. A company buys a new ERP to escape the mess of the old one. There is a heroic go-live. Everyone is relieved. Then the customizations creep back in, the master data drifts, the workarounds pile up, and a decade later someone stands up in a steering committee and says it is time for a new ERP to escape the mess of this one. The platform changes. The mess is remarkably consistent.
AI is the newest reason to do it right this time. It is a good reason too, better than most, because AI does something the old reporting tools never did. It acts on your data. For the first time, the cost of your data problems does not just sit in a dashboard nobody trusts. It posts to the ledger. It screens the candidate. It releases the order. Garbage in used to mean a bad report. Now it means a bad decision, made fast, at scale, by a system that sounds certain.
The gating factor is not the model. It is the data.
The vendors sell AI as the hard part. It is not. The data underneath is, and the research is blunt about it.
Gartner expects organizations to abandon 60% of AI projects through 2026 because the data is not ready to support them, and found that roughly 63% of organizations either lack the right data-management practices for AI or are not sure whether they have them. Precisely’s annual study landed on the number that should stop a CIO cold: 12% of organizations say their data is of sufficient quality and accessibility for AI.

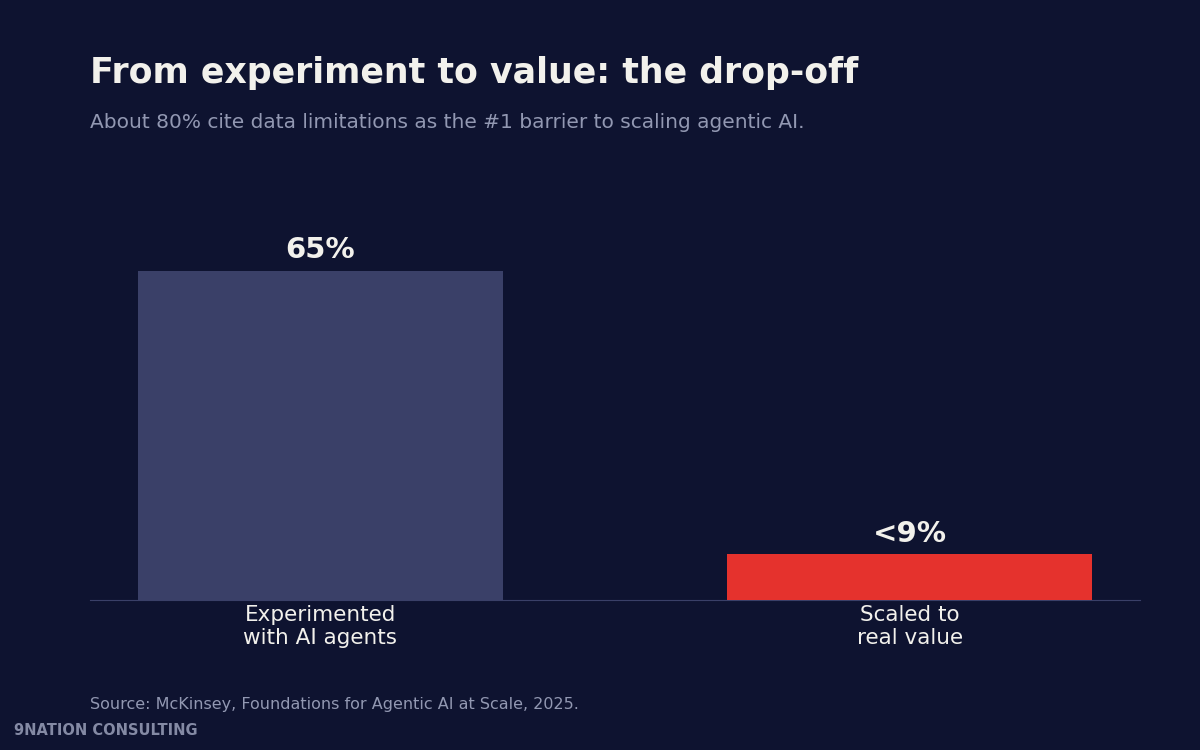
McKinsey found about 80% of companies name data limitations as the main roadblock to scaling agentic AI. Roughly two-thirds have experimented with agents. Fewer than 10% have scaled them to real value. They are not failing on the model. They are failing on data discipline.
Put it together and the picture is clear. The bottleneck in your AI program is not model choice, vendor choice, or compute. It is the unglamorous state of your master data and the discipline of your processes. You can buy the best agents on the market and bolt them onto a foundation that collapses the moment they hit production.
AI on dirty data is not just wrong. It is confidently wrong, and it does not pause to frown at the number the way your best analyst would.
Why confidently wrong is the real risk
A human analyst working with shaky data hesitates. They sense something is off, they caveat it, they go check. An agent does not. Point it at inconsistent vendor records or a cost-center hierarchy that three departments maintain three different ways, and it acts. Cleanly, quickly, with no tell that anything went wrong. The output looks as polished as the correct one.
So the 60% abandoned figure is actually the optimistic reading. Those projects at least failed in the open, before they did damage. The scarier case is the project that ships on a shaky foundation and quietly produces plausible, well-documented, wrong answers for a year before anyone reconciles closely enough to notice.

Your customizations are now an AI tax
Here is the part that connects straight to the migration most of you are already planning. Every non-standard modification you carry, every custom object, every bypass of the supported extensibility layer, used to be technical debt, a vague future problem. It just turned into a concrete near-term invoice, and AI is the line item.
This is what the clean-core push is really about. SAP formalized it in 2025 into a compliance model running from Level A, fully clean, extensions safely outside the core, AI features that switch on as shipped, down to Level D, years of unmanaged direct modification where upgrades are blocked and AI cannot turn on without major remediation first. SAP names data as one of its five clean-core dimensions on purpose. Even if your code is spotless, dirty master data disqualifies you. Oracle built its Fusion agents to run on the suite’s shared data model and governance, a technical dependency rather than a slogan. Workday’s agents only behave on well-governed tenant data. Misconfigured business processes and duplicate workers produce confidently wrong AI either way.
The common thread across all three vendors is the same. Modern AI features assume a standardized, clean data model. Custom code already runs past 30% of the scope in a typical brownfield migration, and none of it makes you readier for AI. Your 2015 customizations do not just cost you on the migration. They cost you again on every AI feature they block.

Brownfield is a word that means carry the mess forward
The fastest migration path is appealing because it is fast. It is also how the mess survives the move. A brownfield lift-and-shift brings your customizations and your data-quality problems straight across the bridge. Duplicate records stay duplicated. Stale records stay stale. You spend a fortune and arrive at the same spaghetti, freshly hosted.
The alternatives, greenfield or a selective bluefield transition that lets you bring some history and leave the rest, exist because enough programs learned this lesson at full price. The point is not that one approach is always right. The point is that the choice should be deliberate, made with your eyes open about exactly which problems you are choosing to carry forward, and paired with real data cleanup before you move rather than a vague promise to fix it later. Later does not come. The hypercare team is too busy keeping the lights on.
The companies winning with AI spend more on the boring stuff
If you need the business case in one line for your CFO, Gartner handed it to you in 2026. Organizations with successful AI outcomes invest up to four times more, as a share of revenue, in data quality, governance, and AI-ready people than the ones getting poor results. The winners are not winning on which model they picked. They are winning on data discipline.
And the discipline is rarer than anyone admits. One industry survey found only 4% of organizations have high maturity in both data governance and AI governance at the same time. Most have a little of one or a little of the other. Almost nobody has the combination that enterprise-scale, agent-driven AI actually needs. That 4% is the gap that will quietly kill most AI ambitions in 2027. Not with a dramatic failure, but with a slow realization that the foundation cannot bear the weight.
What AI-ready data actually takes
None of this is mysterious. It is just work that does not demo well. It starts with real ownership. Every critical data domain, vendor, customer, material, cost center, employee, needs an accountable owner with authority, not a steward who files tickets nobody actions. It means data-quality standards written as commitments, completeness, freshness, accuracy, that domain teams are actually held to. It means treating master data management as a standing discipline rather than a one-time cleanup, because the moment you stop, the drift starts again.
And it means the connective tissue that makes data trustworthy to a machine: lineage you can trace, which regulators increasingly require for high-risk AI anyway, a catalog with enough metadata that an agent and an auditor both know what they are looking at, and an extensibility discipline that keeps the core clean so the platform’s AI can run. Governance of the system architecture and governance of the data have to move together. You cannot sit a Level A clean core on Level D data and expect the agents to behave.
None of this is the exciting part of an AI strategy. All of it decides whether the strategy survives contact with production.
The window is now
The forces are converging in the same eighteen-month window. SAP’s 2027 deadline. The quarterly cadence of the cloud platforms. The rollout of agentic features across every suite. That convergence is inconvenient, and it is also the opportunity. A migration is the rare moment an enterprise gets to make a deliberate architectural choice instead of inheriting one. Clean the data. Rationalize the process. Keep the core clean. Walk into the AI era on a foundation that can hold it.
Or lift and shift, hit the date, declare victory, and find out you spent a fortune to run your old garbage faster, with AI now standing by to explain, very confidently, why the garbage is wrong.
The technology was never going to be the hard part. It never is. The discipline to fix the foundation before someone with a fee incentive tells you it is good enough is the whole game. It is worth having someone in the room who is paid to insist on it.
Sources
Gartner, “Lack of AI-Ready Data Puts AI Projects at Risk” (Feb 2025), for 60% abandoned through 2026 and 63% lacking or unsure of data practices. Gartner (Apr 2026), for successful-AI organizations investing up to four times more in data foundations. Precisely, Fourth Annual Study (2025), for 12% AI-ready, 64% citing data quality, and 67% not fully trusting their data. McKinsey, “Foundations for Agentic AI at Scale” and “Bridging the Great AI Agent and ERP Divide” (2025). DATAVERSITY 2025 Trends in Data Management, for 4% high maturity in both data and AI governance. SAP clean-core model, Levels A to D, SAP News (Aug 2025); PwC S/4HANA migration risks, for custom code past 30% of scope. Oracle Fusion Agentic Applications (Mar 2026); Workday Data Cloud (Sep 2025). �����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������